Управление мастер-данными в микросервисной архитектуре
При работе с микросервисной архитектурой один из сложных вопросов заключается в том, как организовать работу с мастер-данными. Когда у каждого микросервиса своя база данных и микросервисы хотят использовать мастер-данные друг друга, то надо находить баланс между копированием данных и количеством вызовов между сервисами.
Рассмотрим ситуацию:
- Микросервис A поддерживает актуальный справочник городов и предоставляет к нему доступ для потребителей. Только через этот микросервис редактируются данные о городах, а значит А отвечает за эти данные и является мастер-системой по данным о городах.
- Микросервис B предоставляет информацию о маршрутах общественного транспорта, существующих в пределах выбранного города. Микросервису B нужна информация о городах.
Вопрос в том, надо ли микросервису В каждый раз ходить в сервис А за данными о городах? Или иметь свою копию данных? Или самому завести справочник с городами и управлять им? А если иметь копию данных, то как синхронизировать их с микросервисом А?
Есть четыре основных архитектурных подхода к решению этой задачи.
№1 Дублирование мастер-систем
В первом варианте (рис. 1) каждый из микросервисов хранит и поддерживает в актуальном состоянии свой справочник городов.
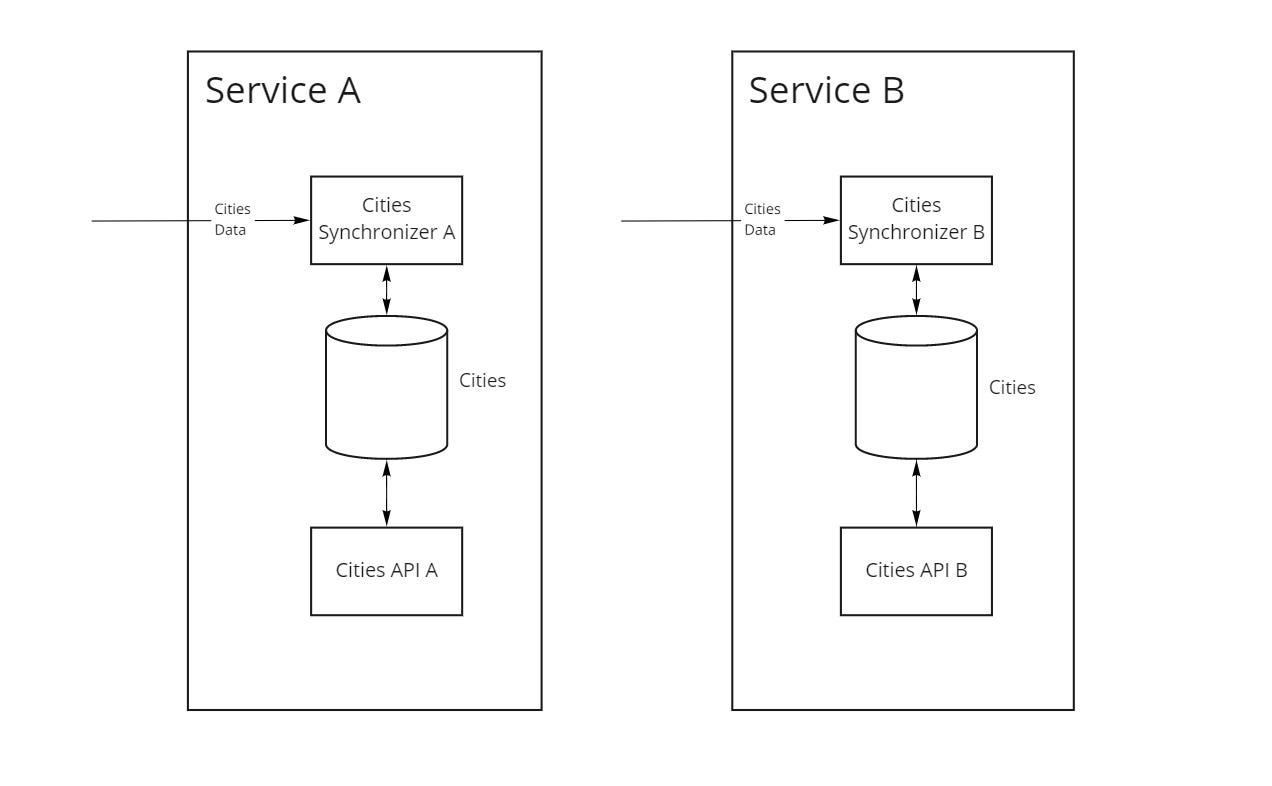
Плюсы подхода:
- каждый микросервис полностью контролирует свой Roadmap работы с данными без оглядки на требования остальных.
Недостатки:
- каждому из сервисов приходится заново реализовывать логику поддержания актуальности данных;
- данные в разных сервисах могут быть рассинхронизированы, например в сервисе A новый город уже добавлен, а в сервисе B еще нет;
- сложности межсервисной интеграции, поскольку структура записей и их идентификаторы не совпадают.
№2 Единственная копия мастер-данных с доступом через API
Во втором варианте (рис. 2) справочник городов есть только в микросервисе A, а микросервис B получает данные через API, имея таким образом всегда актуальные данные.
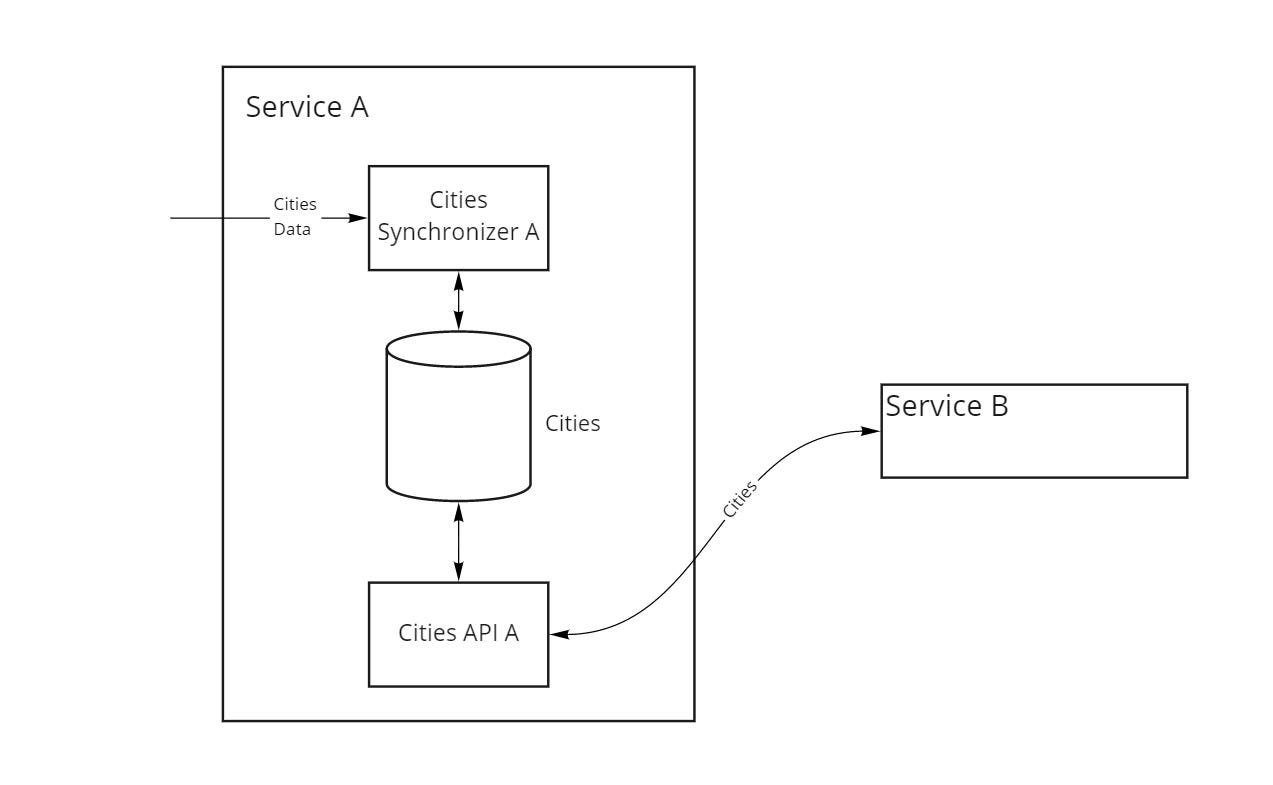
Плюсы подхода:
- все микросервисы работают с одной версией данных;
- микросервисам, читающим данные, больше не нужно заботиться об их актуальности, в нашем примере это задача сервиса А.
Это решение, увы, также имеет и ряд недостатков:
- API микросервиса, в котором находятся данные, должно учитывать требования сразу всех потребителей;
- API микросервиса, в котором находятся данные, может быть перегружено запросами на их получение, что сделает микросервис “бутылочным горлышком”;
- другие микросервисы не знают, когда мастер-данные обновляются, поэтому DDoS-ят микросервис А, чтобы узнать, нет ли новых данных;
- сеть нагружена перегонкой больших объемов одних и тех же данных;
- проблемы с Fault Tolerance: если в нашем примере сервис A “ляжет”, то сервис B останется без данных и, возможно, не сможет продолжить работу.
№3 Организация Data warehouse (DWH)
В третьем варианте (рис. 3) справочник городов редактируется только через микросервис A, который в свою очередь сливает его изменения в специальное хранилище данных (DWH). К этому хранилищу, в свою очередь, ходят все остальные микросервисы системы, в нашем примере это микросервис B.
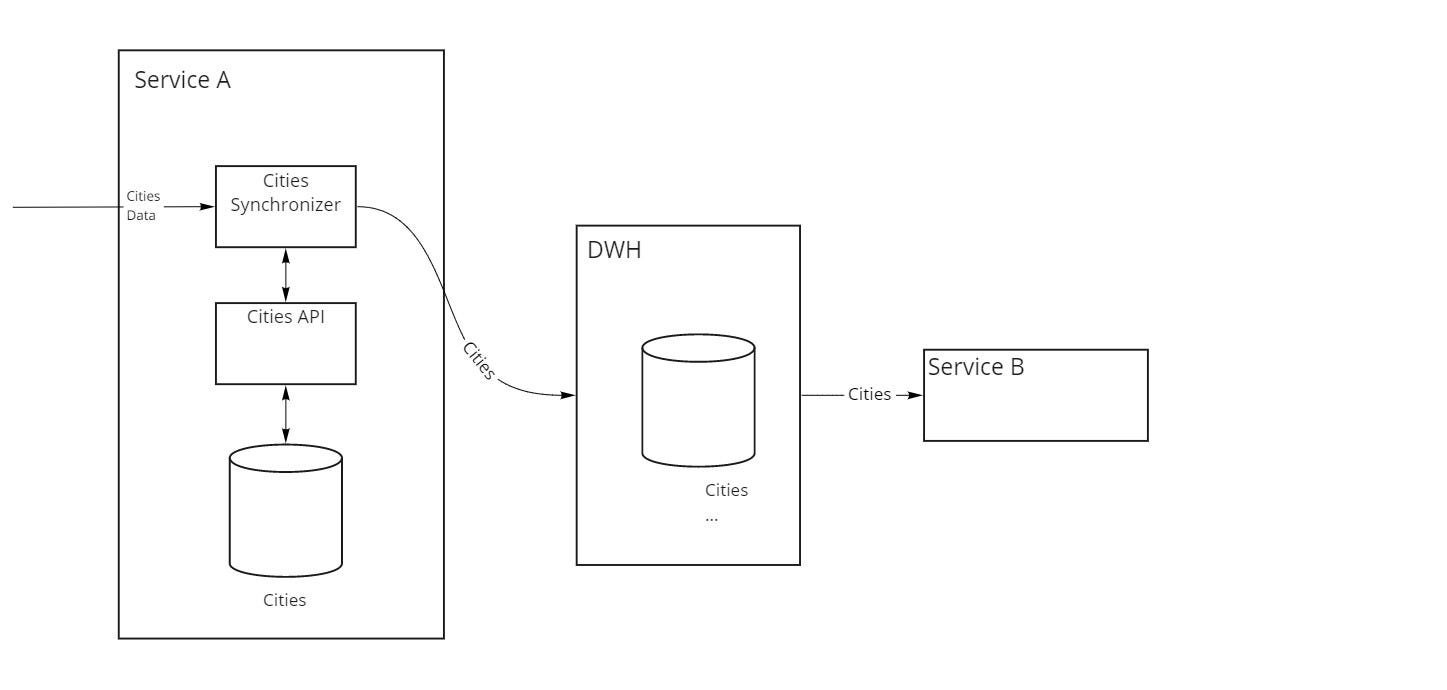
Плюсы подхода:
- все микросервисы работают с одной версией данных;
- микросервисам, читающим данные, не нужно заботиться об их актуальности, в нашем примере это задача сервиса А;
- поскольку все системы сливают данные в DWH, по ним можно строить сложные аналитические отчеты и выгрузки.
Хотя плюсов у данного варианта достаточно много, за них нужно платить:
- данные обновляются в DWH с некоторой задержкой, что может стать проблемой, если для бизнеса важно, чтобы эта задержка была нулевой или близкой к нулевой;
- DWH является высоконагруженной частью системы, как на чтение так и на запись, поскольку все владельцы данных в него пишут, и все желающие из него читают;
- опять же проблемы с Fault Tolerance, поскольку для многих DWH — единственный источник данных;
- сложно добавлять новые источники данных в DWH, поскольку либо DWH под всех подстраивается, либо все подстраиваются под требования DWH, а создать универсальное во всех смыслах решение с учетом нынешнего “зоопарка” технологий весьма сложно.
№4 Мастер-система отдает данные через очереди
В четвертом варианте актуальный справочник городов редактируется только через микросервис A. Микросервис B хранит у себя копию справочника, который постоянно актуализируется из микросервиса А через очередь сообщений с обновлениями справочника.
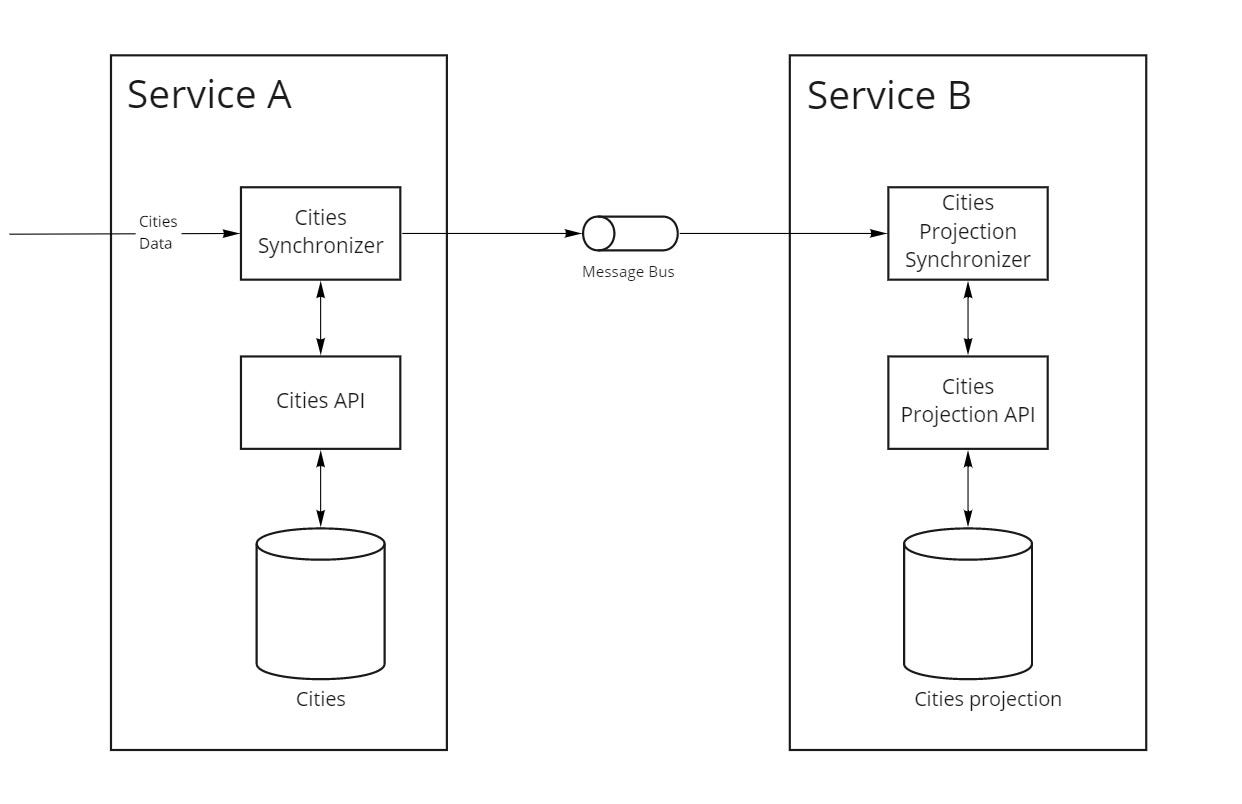
Такой подход решает несколько проблем:
- мастер-система больше не перегружена постоянными синхронными запросами на получение данных;
- если микросервис A станет недоступен, то микросервис B будет работать со своей копией данных.
4.1. Концепция
Поделим микросервисы, работающие с данными на две группы:
- микросервис, который имеет возможность записывать данные — мастер-система или владелец данных. В нашем примере для справочника городов сервис A— мастер-система;
- микросервисы, которые читают данные — потребители.
Как поддерживать актуальность копии данных в потребителях? Возможны варианты, которые сводятся к pull- или push-подходу:
- при pull-подход уже рассматривали в разделе “№2 Единственная копия мастер-данных с доступом через API”;
- при push-подходе (рис. 4) master-система сама уведомляет нас об обновлении данных в справочнике через сообщение в очереди.
4.2. Реализация
С точки зрения мастер-системы, она может выгружать в очередь сообщений:
- полный слепок обновленной сущности;
- только изменившееся поле.
С точки зрения потребителей, хранение мастер-данных может быть реализовано тремя способами:
- хранение только актуальных данных;
- хранение слепков данных на моменты времени их изменения, если вам нужна история. В случае использования Kafka механизм хранения перекладывается на шину;
- хранение транзакций изменений, если вы используете Event Sourcing.
Выбор конкретного подхода для мастер-системы и потребителя зависит от ваших бизнес-требований.
4.2.1. Конвенции именования очередей
Именование очередей становится важным процессом. Так как количество очередей исчисляется сотнями, то важно упорядочивать их созданием и именованием, чтобы не запутаться.
Важно, чтобы возможность создавать очереди и настраивать правила проверки именований, была у ограниченного круга лиц (администраторы), которые будут следить за соблюдением конвенций. В обязанности администраторов очередей обычно входит и создание биндингов до нужных обменников.
Каждая очередь создается в трех экземплярах (рис. 5):
- api.{мастер система}.{ключ данных}.{система потребитель} — основная рабочая очередь, через которую приходят все изменения в реальном времени. У этой очереди всегда должен быть потребитель;
- flood.{мастер система}.{ключ данных}.{система потребитель} — очередь для разовой проливки исторических данных;
- error.{мастер система}.{ключ данных}.{система потребитель} — очередь ошибок системы потребителя, содержит исходное сообщение и ошибку, которая возникла при обработке сообщения. После исправления ошибки, сообщение переотправляется в основную очередь (api.*) для обработки специальным механизмом.
Очередь ошибок нужна для:
- последующей ручной отладки;
- предотвращения потери информации (ее обработка будет лишь отложена);
- предотвращения остановки обработки последующих сообщений в очереди.
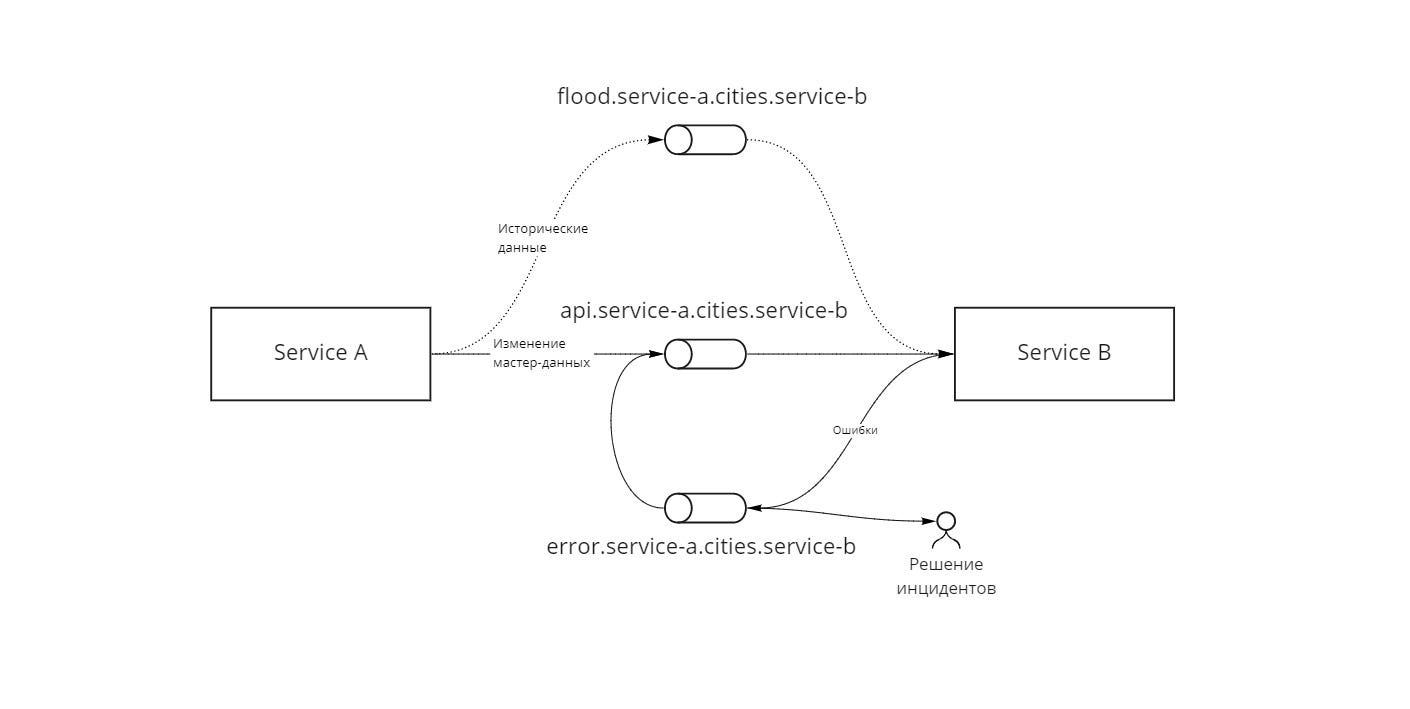
Мастер-система знает ключ маршрутизации, по которому пушит сообщения api.{мастер система}.{ключ данных}.*. Потребители читают уже конкретно из своей очереди api.{мастер система}.{ключ данных}.{система потребитель}.
Примеры конвенций ориентированы на RabbitMQ, однако могут быть адаптированы и для других шин.
4.2.2. Первоначальная проливка данных
При появления нового потребителя, встаёт вопрос о разовой проливке мастер-данных. Для этого чаще всего используют 2 подхода:
- разовая постраничная выгрузка всех данных через API;
- разовая постраничная проливка всех данных через шину сообщений.
Оба варианта примерно равны по трудозатратам. Выбор зависит от конкретных бизнес-требований.
4.2.3. Версионирование (историчность) данных
В некоторых случаях потребителю важно знать состояние данных на определенный момент времени. Например, город Санкт-Петербург когда-то назывался Ленинградом, а гипотетическому потребителю важно точно знать как какой город назывался в конкретный момент времени.
Для реализации такого требования потребителю потребуется уметь хранить версии записей с указанием периода действия каждой из них, а мастер-системе выгружать на шину дополнительную meta-информацию, по которой читатели могут определить, создается ли новая версия записи или правится последняя действующая.
4.3. Плюсы и минусы подхода
Плюсы:
- за актуальность данных отвечает мастер-система, она является единственным источником правды;
- мастер-система и микросервисы-потребители независимы и ничего не знают друг о друге;
- при работе с данными в системе нет высоконагруженных микросервисов, потому что нагрузка уходит на уровень инфраструктуры;
- возможность горизонтально масштабировать потребителей очередей;
- часть работы по обеспечению Fault Tolerance перекладывается на шину сообщений;
- шина предоставляет возможности управления рассылкой сообщений.
Минусы:
- eventual consistency может стать проблемой, если скорость обновления мастер-данные должна быть нулевой или близкой к нулевой и это критично для бизнеса;
- более высокий порог входа, т.к. решение требует дополнительных организационных и технических решений;
- высокая стоимость первоначальной настройки.
Вывод
Каждый вариант имеет свои сильные и слабые стороны. Общие рекомендации при выборе следующие:
- выделять мастер-системы для данных и добиваться того, чтобы данные редактировались только в них;
- при работе с данными избегать создания “бутылочных горлышек”, так как каждый новый потребитель может обрушить систему.
И частные:
- если впереди маячит перспектива построения сложных отчетов и аналитических выгрузок, то без DWH не обойтись;
- если eventual consistency становится проблемой, то стоит обратить внимание на второй вариант;
- во всех прочих ситуациях стоит реализовывать вариант с раздачей данных через очереди.
В нашей практике мы обычно реализуем четвертый вариант с той лишь оговоркой, что иногда в связи со сложностью интеграции с очередями и ограничениями временного бюджета, сначала реализуется pull-подход и уже потом push-подход.