What is worth and what not to do in the tests
Or how to write long-lived tests
This article is based on my personal experience in writing tests for various projects. Now I want to describe and systematize some tricks and techniques which helped me.
Before I start, I want to specify a few things. Firstly, most of the described refers to large projects, because of implementation takes time and patience. Secondly, by “ long-lived tests” I mean the tests whose support is more useful to the project than their removal or rewriting from scratch after a breaking changes and which will exist as long as there exists a feature checked by them. And now, when we are on the same wave, I can start.
Imaginary application
Since this article will focus on practical techniques for writing tests I think that it’s better to demonstrate them by the example of an imaginary application worked with real domain. So in this article all tests will verify behavior of the application which calculates the costs of the books printing.
More formally, there is a Web API, which can calculate for each order for printing books the printing cost and date when the order is going to be finished. Because books printing is a complex task its cost and finish date depends on many factors such as:
- edition type;
- cover type;
- size of the book;
- paper type;
- illustrations count;
- size of the font;
- copies count;
- etc.
That is why testable application has flexible system of the cost calculators in order to correctly take into account the various parameters during the calculations. The correctness of their work will be covered by tests. And now when domain was described we can start.
Explicitly specify only what affects the test result
As was mentioned before, costs of the order for printing is a sum of costs by various items, for example, cost of the paper needed for printing, cost of printing the illustrations, etc. The implementation of this concept in the code may look like this.
It is necessary in this environment to write tests for the calculator of the expenses for designer’s work over the book. In the simplest case costs of the designer’s work depends on type of the edition and cover of the book. So, at first glance, tests can be implemented without any additional constructions as they are shown below.
However, this simple approach has several disadvantages. Firstly, on such tests it is difficult to understand which parameters determine the outcome. Secondly, it is also difficult to understand which of the constructor parameters corresponds to the transmitted value. Situation will become especially complicated if a constructor has a lot of parameters with the same type. Thirdly, any alteration in the signature of the constructor will cause a lot of changes or even compilation errors in the tests.
The first and the third disadvantages can be easily overcomed by creating derived class from PrintOrder with constructor which predefined default values for their parameters. Unfortunately, for elimination of all three disadvantages it is necessary to use more complicated approach. The main idea is to create a factory, which can produce objects, with parameters configured via fluent syntax. Values are explicitly specified only for the object’s used parameters, the rest of the parameters use predefined default values.
Such approach allows to avoid disadvantages which were mentioned early, moreover it increases readability of the tests’ code.
And in addition to that has been said, created generators give an opportunity to create and store reference objects that can dramatically reduce initialization part of the tests and, as will shown in the next section, can also make results verification more complete.
Avoid multiple asserts during objects verification
Sometimes it is necessary to verify correctness of the complex object or collection of objects. In our case, result of the client’s order processing (printing costs, total pages count, estimation for finish date, etc) should be verified. This task looks rather simple and code for solving it can be written in a short time.
Such implementation is very simple, but unfortunately there are some shortcomings in it. Firstly, tests can discover only one mistake per running because verification will stop after first wrong assertion and developer ought to run test over and over until all mistakes will be corrected. Secondly, such test cannot be parameterized and reused because it can verify state of only one object and this cause increasing number of tests which differs only in verification part. Thirdly, if any field is added to verifiable object it will be necessary to modify verification part of all tests which verify its state and it is easy to forget about it. And fourthly, reference object for verification can’t be extracted from one test and reused in other as input data. This list looks too long, but all mentioned shortcomings can be fixed by constructing reference objects via generators and using external objects comparers such as CompareNETObjects.
Constructing reference objects via generators makes them reusable and test can be easily parameterized as was shown in second version of ShouldVerifyPrintOrderProcessingResultsMapping test. Moreover, usage of the external objects comparer can reduce the procedure of the verification of the object correctness to several lines of code.
Test only what actually should be tested
Before this were discussed techniques which affects single tests or small groups of tests, but now and further some approaches which can optimize testing process of the whole project and make tests more stable and long lived will be discussed. In the common sense, the main goal of the writing tests is to fixate via them the application behavior and check it automatically. However, sometimes restrictions imposed on the application in tests are too tight and redundant that can costs hours of tests fixing even in case of the small changes in application behavior. Moreover, in such cases, broken tests are sometimes simply deleted, which makes the time, spent for writing them, lost without purpose.
Existence of the described situation means that the tests were written not from the point of view of the application domain. Now I know two causes which can lead to this (maybe in the future I’ll discover more😉) and I’ll explain them on small examples.
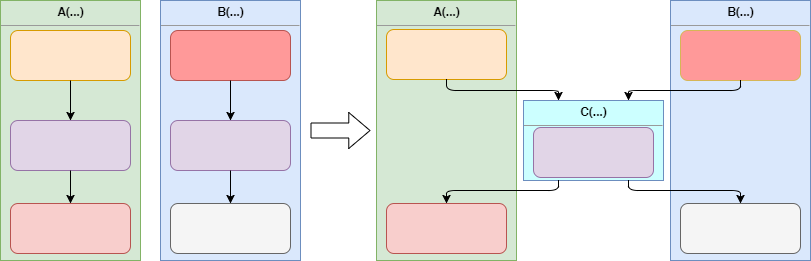
Let’s imagine that in order to follow to DRY princip, common parts of the two methods of the some class were extracted and placed in the third method. This step makes the implementation cleaner and more compact, but covering of the new method by automated tests will be a good idea only if results of its working means something in the terms of the application domain. Otherwise, created method will be only implementation trick which behavior will be modified or even method itself will be removed as soon as new ideas will come to developers. Therefore tests for such method will be modified very frequently or will be removed at all. The cause of this in fixation of the behavior, which means nothing in terms of the application domain.

The second cause needs a little bit longer example. Let’s imagine that it is necessary to write automated tests for algorithm which places illustration in the text. Placing illustration is a tricky process because the possibility of placing the illustration exactly on the place which was specified by customer depends on many factors such as size of the page, position of the illustration on the page, position of other illustrations, etc. So, by agreement with customer, illustration should be located no further than at the beginning of the page following the required. However in tests was fixed exact position of the illustration in text and after alteration in algorithm, which in some cases makes possible to place illustrations closer to required position via resizing them, tests will be broken. The cause of this in fixation of the requirements to algorithm results, which were superfluous from the point of view of the application domain.
In the given examples in tests was fixated the behavior, which was caused not by the requirements of the application domain, but by the features of their implementation and when requirements were changed, the tests began to fall. That is why it is better to write tests from the point of view of the application domain, because then it is impossible to test behavior that is redundant or meaningless in it. I think, the appropriate term for this is Domain Driven Testing (DDT).
Hierarchical testing instead of mocking
The behavior of any complex object that is checked in isolated autotests depends on the input of the test and consists of the behavior of the object itself and the behavior of its dependencies. It makes tests stable and predictable. However, the dependencies of objects can be divided into two groups. Firstly, uncontrolled dependencies, whose behavior depends on some external uncontrolled factors, for example, a service that determines the price of the paper used for printing illustrations in the online store. Secondly, controlled dependencies, whose behavior completely depends on the input of the test, for example, a service that places illustrations in the text. Therefore uncontrolled dependencies are replaced by mock objects, there are several possible approaches for handling controlled dependencies in tests.
Let’s imagine that it is necessary to write a tests for a class which calculates cost of printing illustrations, and it depends on mentioned early service for illustrations placing and service for paper price downloading. The first approach for handling of the controlled dependencies is to mock them too, like uncontrolled dependencies.
Code looks rather regular and all dependencies seem to be under control of the developer. Unfortunately, this is not entirely true and used approach has several disadvantages. Firstly, actual behavior of the controlled dependency for the passed data can be different from the setupped behavior of the mock dependency and the tests will test the behavior not corresponding to reality and be green. Moreover, another developer can change dependency behavior and not change mock’s setups in tests, that after some time can be a big trouble when new developer will join team and want to understand code behavior by tests. Secondly, maintaining of such code is rather painful because if developer changes something in the signature of the mocked method, he will be forced to change all setups for this mocked method because of appeared compilation errors. Both mentioned factors eventually lead to a decrease in the speed of development of features and the devaluation of tests, pushing them closer to the boundary behind which the removal is located. So let’s look to the second approach.
The key idea of the second approach is do not mock controlled dependencies but to use their implementations. This avoids the disadvantages of the first approach described above, but increases the complexity of generating input test data, because for it now it is necessary to take into account the behavior of all controlled dependencies of the tested object. However, not everything is so scary, this difficulty can be overcomed by using hierarchical testing.
The essence of hierarchical testing in this case is that at the time of writing tests for some class tests for all of its controlled dependencies are already written (and if it is not, they should be written) and their input data can be used to generate input data in tests of the checked class. Therefore, generating of the tests input data become the fixation of knowledge about code behavior.
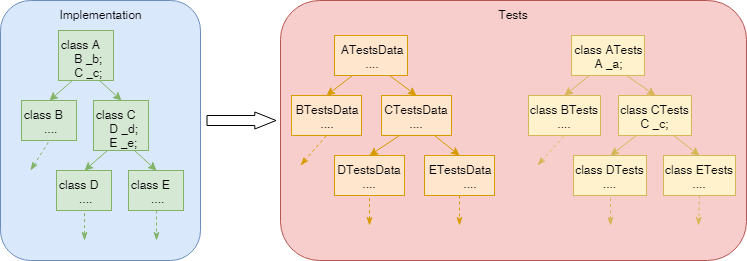
Hierarchy of code classes produces hierarchy of tests and their input data and each test on each layer of this hierarchy checks not only the class for which it was written but also recursively all of its controlled dependencies and their integration. At the top of this structure, if we are speaking about Web API, will be placed integration tests, checking the written application as a whole. About this kind of tests I wrote in my previous article.
Conclusion
All described tricks and techniques comes from practical experience. They were solutions for some problems happened during development of the real projects. However, I suppose that before using them in specific cases, you need to assess how they are applicable in your situation. The best counselor during development is your own logic and understanding what problem you are actually solving now, they should be in first place and ways of implementation in the second. And, of course, tests for code, not code for tests.