
Collecting Public Procurement Data with the help of Microservices
Public procurements are continuously being published on multiple public internet resources. Information about new procurements and updates are published with different frequencies or depends on a customer’s activity. For example, sometimes there is no new information, but at other times there are too many changes being made at one time.
The web service's IT architecture should smooth out overloaded peak times and decrease the use of cloud resources during idle times as well. We applied microservice architecture to manage the load depending on the power of an incoming information stream.
We developed the pipeline for delivering analytics information on time to the users:
- Data collection services aka "spiders"
- Download HTML from found pages
- Extract information and save it in different datastores
- Analyze data
- Show analyzed data on the web service.
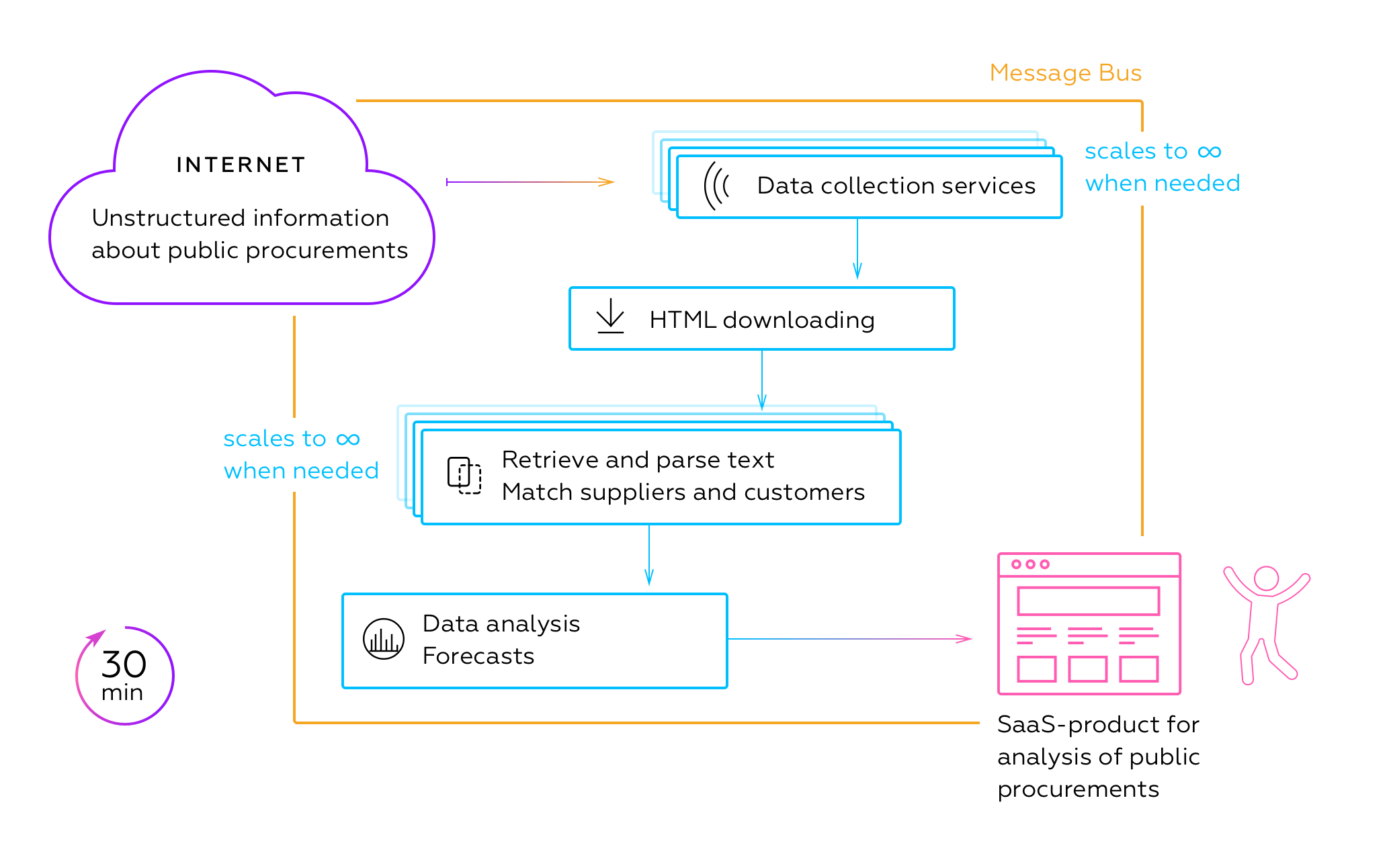
Byndyusoft built infrastructure on Amazon Web Services to automatically provide the scaling out of cloud resources.

Information in the analytical system is almost the same with public data sources. The delay in new information publicized is less than 30 mins.
Microservices continuously collects the following data:
- Data on new public procurement tenders and auctions
- Changes in current tenders and auctions
- Changes in details of suppliers and customers
- Data on signed agreements
If the power of the information stream is suddenly increased, the system automatically scales out bottlenecks by creating more instances of an overloaded service.